
The new coder model – Qwen2.5 32B coder (also models of various sizes: 0.5B / 1.5B / 3B / 7B / 14B, and quantized models in GPTQ, AWQ, and GGUF formats).
Key Features
* Top-tier performance, surpassing proprietary models like GPT-4o
* Highly competitive results in benchmark evaluations (HumanEval, MBPP, LiveCodeBench, etc.)
* Models available in various sizes: 0.5B / 1.5B / 3B / 7B / 14B
* Quantized models in GPTQ, AWQ, and GGUF formats
Qwen with Bolt and Ollama
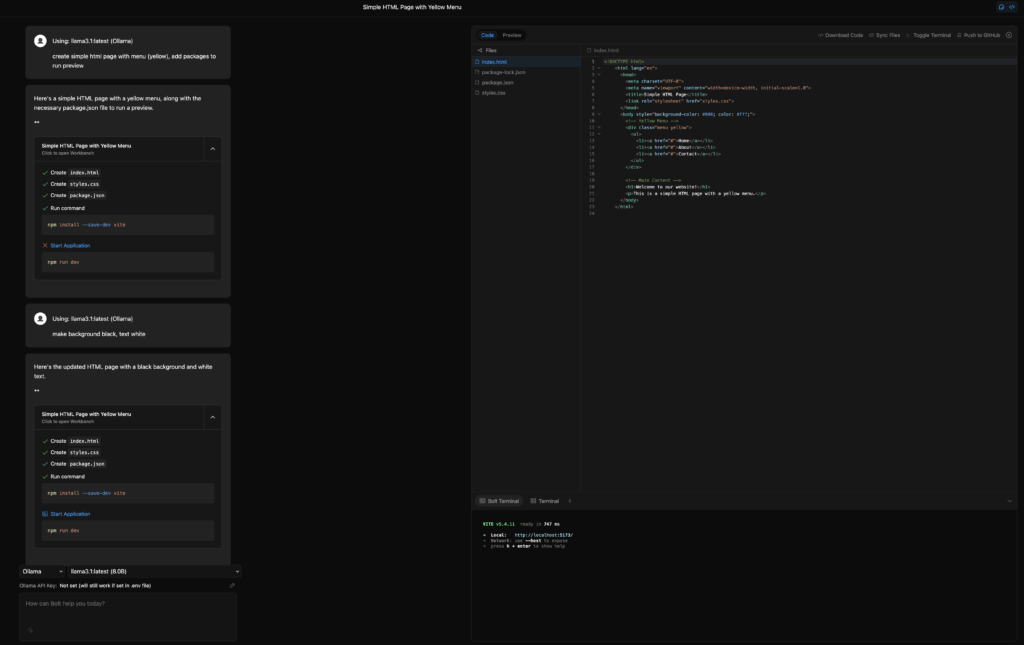
You can run Bolt (from e.g. pinokio.computer) locally, with 1-click, and enjoy 100% local LLM coding. Use Qwen with Bolt to perfectly display app previews on Ollama.
I wasn’t able to install Bolt on Windows with Pinokio (some strange issues with C++ redistributable libraries and Vite), so I dropped this idea and tried it on Mac with the 32B model. Of course, I had RAM problems, so I dropped to llama3.1, and finally, I got something working. Preview code goes through StackBlitz, so it’s not fully offline. Also, I had issues with replacing data in files if I modify them manually. If you want to give it a try: https://github.com/coleam00/bolt.new-any-llm it’s very good described how to run it w/o Pinokio.
I saw also on the Internet that it’s possible to use artifacts with OpenWebUI, but I’m rather sceptical about it after seeing that Bolt solution.